
Every AI system you interact with today — ChatGPT, Claude, Gemini, Copilots, AI-powered search — runs on one idea: predicting the next word. That single mechanism, repeated billions of times across trillions of words, produces systems capable of reasoning, writing, coding, and conversing at a level that would have seemed impossible five years ago.
This post explains how language models actually work — from the mathematical foundation to the architecture to the training process — and why it matters for business leaders and practitioners who want to move beyond the hype and understand what they are actually deploying.
What is a Language Model?
A Language Model is a probabilistic system that learns patterns in language and assigns likelihoods to sequences of words (or tokens).
At its core, it answers a simple but powerful question – “How likely is this sequence of text?”
Language models achieve this by learning statistical regularities from massive text corpora—capturing grammar, structure, context, and meaning in human language.
Mathematical Foundation
A language model is not a database of knowledge—it is a system for modeling language as probability. Formally, a language model defines a probability distribution over a sequence of words:
From Probability to Prediction
This equation may look mathematical, but conceptually it means something simple: the model builds a sentence one word at a time, always using prior context. A language model decomposes the probability of a sequence using the chain rule, expressing it as a product of conditional probabilities:
In simple terms, the model predicts each token based on all the tokens that came before it. This step-by-step prediction process is the core mechanism behind autoregressive text generation.
This means – Given previous words, predict the next word Repeat this process to generate full sentences, This means that every possible sentence can be assigned a probability. More natural and meaningful sentences tend to have higher probabilities, while incorrect or incoherent sequences have lower probabilities. This simple yet powerful idea underpins everything from basic autocomplete features to modern AI systems.
For Example Consider the sentence: “The sun rises in the”
A language model might assign probabilities like:
- east → 0.85
- west → 0.10
- sky → 0.04
- banana → ~0.00
The model selects or samples from these probabilities to generate text.
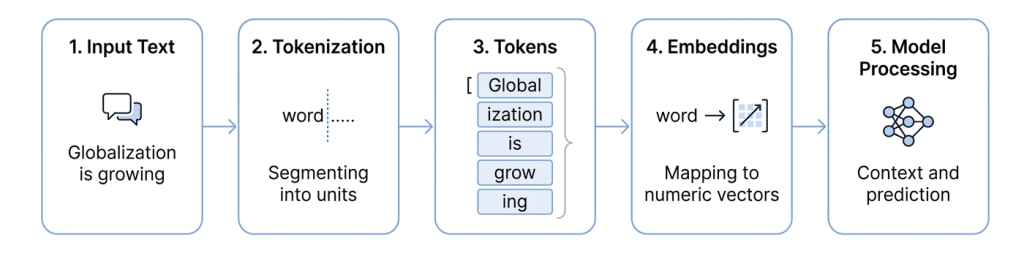
Tokens: The Building Blocks of Language
Language models do not process raw text directly—they operate on tokens, which are smaller units of text. These tokens are typically subword units, rather than full words, allowing models to handle language more efficiently and flexibly. A token can represent:
- A full word (e.g., “sales”)
- A subword (e.g., “trans” + “form”)
- Or even a character in some cases
Examples of Tokenization
- “transforming” → “transform” + “ing”
- “unbelievable” → “un” + “believ” + “able”
- “globalization” → “global” + “ization”
- “AI-driven” → “AI” + “-” + “driven”
Why Sub-word Tokenization Matters
Modern language models use techniques such as Byte Pair Encoding (BPE) or WordPiece to break text into subword tokens. This design provides several key advantages:
- Efficient vocabulary management – Instead of storing millions of full words, models operate with a manageable vocabulary (typically ~30K–100K tokens).
- Handling unseen or rare words – New or uncommon words can be broken into known sub-words, allowing the model to still interpret them effectively.
- Better generalization across domains – Whether it’s business terms, product names, or technical jargon, sub-word tokenization enables flexibility.
- Language-agnostic capability – The same approach works across multiple languages, making models scalable globally.
- Efficient computation – Smaller, reusable token units make training and inference more efficient.
Language models do not “read words” the way humans do; instead, they process patterns of tokens. As a result, they can understand and generate new words they have never explicitly seen before, adapt seamlessly across different industries such as retail, finance, and healthcare, and operate across multiple languages using the same underlying architecture.
Embeddings: How Does AI Translate Words into Numbers?
Before any processing begins, tokens are transformed into numerical representations known as embeddings.
These embeddings capture the semantic meaning of language by representing words and subwords as vectors in a high-dimensional space. As a result, tokens with similar meanings are positioned closer together, enabling the model to understand relationships, context, and nuances.
This transformation is what makes language computable, allowing models to move from raw text to meaningful interpretation and prediction.
What Does a Language Model Actually Learn?
What emerges is not memorization, but a compressed representation of how language—and to some extent, the world—behaves.
At its core, a language model does not memorize sentences—it learns patterns and structures of language from massive text data. Specifically, it learns:
- Statistical relationships between words → which words tend to appear together
- Grammar and syntax → how sentences are structured correctly
- Contextual meaning → how meaning changes based on surrounding words
- Long-range dependencies → how earlier parts of a sentence influence later parts
- Usage patterns and style → tone, phrasing, and domain-specific language
In essence, a language model builds a probabilistic map of language, allowing it to generate text that is coherent, context-aware, and human-like.
In simple words, a language model does not “store knowledge” like a database—it learns how language behaves. This is why it can:
- Generate entirely new sentences
- Occasionally produce fluent but incorrect responses
- Adapt to different contexts and tones
The Transformer + Attention: Engine Behind Modern Language Models
The Transformer architecture is the core engine behind modern language models. It enables models to process entire sequences of text simultaneously and learn relationships between words efficiently.
The Transformer architecture, introduced in the landmark 2017 paper “Attention is All You Need”, solved a fundamental problem with earlier models: they processed text sequentially, meaning they struggled to connect words that were far apart in a sentence. Transformers eliminated this bottleneck by processing all tokens simultaneously.
Here’s what happens inside a single Transformer block:
Step 1 — Multi-Head Self-Attention. Every token in the sequence looks at every other token and asks: “How relevant are you to me?” This is computed using three learned vectors per token — Query (what am I looking for?), Key (what do I offer?), and Value (what information do I carry?). The dot product of Query and Key produces an attention score, which is normalized via softmax so all scores sum to 1. The output is a weighted combination of Value vectors — meaning each token’s representation is now informed by the entire sequence.
Running this process across multiple “heads” in parallel lets the model simultaneously learn different types of relationships — grammatical agreement, coreference, positional proximity, and semantic similarity — all within the same layer.
Step 2 — Feed-Forward Network. After attention, each token’s updated representation passes through a small two-layer neural network independently. This is where the model applies non-linear transformations that allow it to encode more complex patterns.
Step 3 — Residual Connections & Layer Normalization. Both steps above are wrapped with a residual connection (the input is added back to the output) and layer normalization. This stabilizes training and allows gradients to flow cleanly through dozens of stacked layers.
A modern LLM stacks anywhere from 12 to 96 of these blocks. Each layer refines the model’s understanding — early layers tend to capture syntax and local patterns, while deeper layers encode abstract reasoning and semantics.
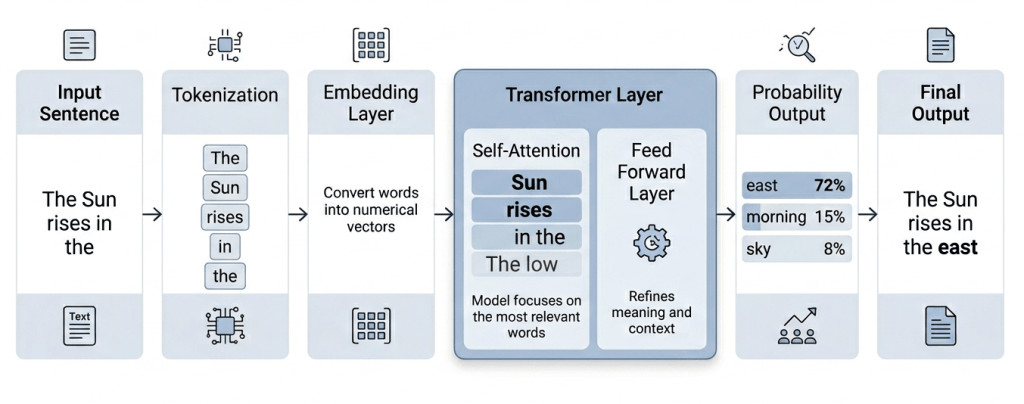
At a high level, the process works as follows:
- Input tokens are converted into embeddings, which represent words as numerical vectors
- These embeddings pass through multiple Transformer layers, each refining the model’s understanding of context
- Within each layer, the model uses self-attention to determine how much focus to give to different tokens in the sequence
- The output is a set of contextualized representations, which are then used to predict the next token
Example – “The Sun rises in the …” The model focuses more on:
- “Sun” → high importance
- “rises” → high importance
- Leading to prediction: “east”
Unlike earlier models that processed text sequentially, Transformers analyze the entire context at once—making them significantly more powerful for understanding language.
Attention: How Models Understand Context
The key innovation in the Transformer is self-attention — and it is worth understanding clearly because it is the mechanism that gives language models their power.
Each token generates three vectors: a Query (what am I looking for?), a Key (what do I offer?), and a Value (what information do I carry?). The dot product of a token’s Query with every other token’s Key produces an attention score — a measure of how relevant each other token is. These scores are normalised and used to produce a weighted combination of Value vectors, giving each token a new, context-aware representation.
Example: In a sales report containing the sentence “Our spring promotion drove a spike in volume but compressed margin across the portfolio”, the word margin could refer to profit margin, page margin, or margin of error depending on context. Self-attention resolves this instantly: the tokens promotion, volume, compressed, and portfolio all score highly against margin‘s Query vector, anchoring its meaning unambiguously to commercial profitability — without any hand-coded rules or lookup tables. The same mechanism works across every domain: a model reading a trade spend summary, a sell-in forecast, or a retailer negotiation brief will correctly resolve ambiguous terms based purely on the surrounding context it has learned to attend to.
Multi-head attention runs this entire process in parallel across multiple heads, each learning a different type of relationship. One head might track which pronoun refers to which noun. Another tracks subject-verb agreement. Another tracks semantic similarity across the sentence. Their outputs are concatenated and projected, giving the model a richer understanding than any single attention pass could provide.
Pre-training and Adaptation
Building a capable language model happens in two distinct phases — and the difference between them matters enormously for how the model behaves in practice.
Phase 1: Pre-Training
In pre-training, the model is trained on a massive corpus of text — web pages, books, code, scientific papers, and more — spanning trillions of tokens. The training objective is deceptively simple: predict the next token given all previous tokens. This is called autoregressive or causal language modelling.
Through billions of iterations of this prediction task, the model is forced to internalize grammar, factual knowledge, reasoning patterns, coding conventions, and domain-specific language — not because it was explicitly taught these things, but because they are all implicit in the statistical structure of human-generated text. The result is a powerful but unaligned base model: it can complete text fluently, but it has no concept of helpfulness, safety, or following instructions.
Phase 2: Adaptation & Alignment
The base model is then specialized through a series of fine-tuning steps:
Supervised Fine-Tuning (SFT) — Human annotators write high-quality example responses to a diverse set of prompts. The model is fine-tuned on these demonstrations, teaching it the format and style of a helpful assistant.
Reinforcement Learning from Human Feedback (RLHF) — Human raters compare pairs of model outputs and indicate which is better. A separate “reward model” is trained on these preferences. The language model is then optimized using reinforcement learning (specifically Proximal Policy Optimization, or PPO) to generate responses that score highly according to the reward model. This is how models learn to be helpful, honest, and appropriately cautious.
Constitutional AI (CAI) — Developed by Anthropic, this technique reduces reliance on large volumes of human labelling. Instead, the model is given a written set of principles (a “constitution”) and uses AI-generated feedback — rather than human feedback alone — to evaluate and revise its own outputs. This makes alignment more scalable, transparent, and consistent.
These steps are what transform a raw text predictor into the AI assistants that feel responsive, safe, and genuinely useful in practice
Context Window: The Model’s Working Memory
The context window defines how much text a language model can consider at once when generating output. It is, in effect, the model’s working memory.
The model receives a sequence of tokens — your prompt plus any prior conversation — and can only draw on information within this fixed window. Everything outside it is invisible.
Why context window size matters for business:
- Long document processing — Larger windows allow the model to read entire contracts, reports, or transcripts in a single pass without losing earlier information.
- Coherent conversations — The model can maintain context across a long back-and-forth without losing the thread of what was established earlier.
- Cross-section reasoning — With sufficient context, the model can connect information from different parts of a document — essential for tasks like due diligence, summarisation, and compliance review.
Context windows have grown dramatically: from 4,000 tokens in early GPT-3 to 128,000 in GPT-4, 200,000 in Claude 3, and over one million in Gemini 1.5. As windows grow, language models become capable of handling more complex, real-world tasks with less pre-processing overhead.
One important caveat: attention is computationally expensive — it scales quadratically with sequence length. Longer contexts cost more to run. Techniques like Retrieval-Augmented Generation (RAG), which inject only the most relevant information into a shorter context, are widely used in production deployments to manage this tradeoff.
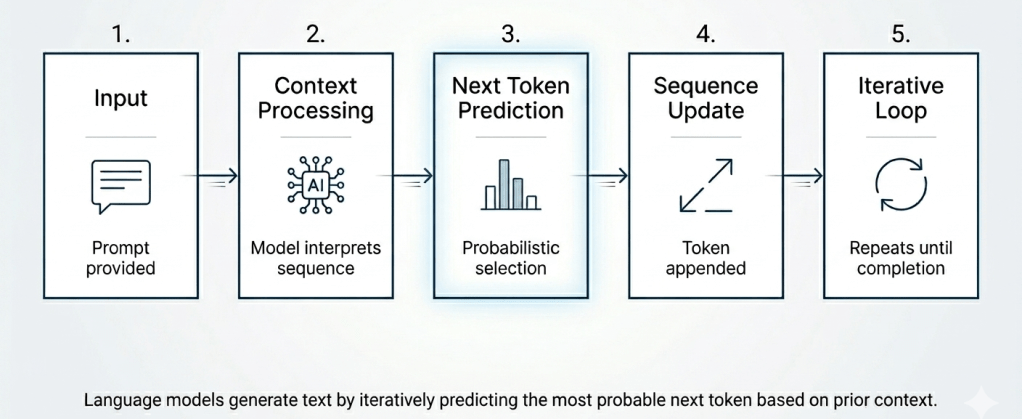
How Language Models Generate Text
Once a prompt is given, text generation follows a repeated loop:
- The prompt is tokenised and converted to embeddings
- The full sequence passes through all Transformer layers
- The final layer produces a probability distribution over the vocabulary
- A token is sampled from this distribution (controlled by temperature, top-p, or top-k settings) . The new token is appended to the context
- The loop repeats from step 2 until the model generates an end-of-sequence token.
The important thing to remember is that the model is not writing with a full outline in mind. It is continually extending a sequence through context-conditioned prediction. Coherence emerges from the quality of the learned probability model and the richness of the context, not from a symbolic plan stored in advance.
Three sampling parameters give you control over the output:
- Temperature — scales the probability distribution. Low temperature makes output deterministic and focused. High temperature introduces more variety and creativity.
- Top-p (nucleus sampling) — restricts sampling to the smallest set of tokens whose combined probability reaches a threshold p. Ignores the long, implausible tail.
- Top-k — restricts sampling to the k most likely tokens at each step. Simple and effective.
Understanding these parameters matters in production: the right settings vary significantly depending on whether you want precise, factual outputs (low temperature) or creative, generative ones (higher temperature).
Why Do Language Models Make Mistakes?
Understanding limitations is as important as understanding capabilities — especially for any organisation deploying these systems in consequential workflows.
Hallucination – Language models generate text by predicting what comes next based on learned patterns, n ot by retrieving verified facts. This means they can produce responses that are fluent, confident, and completely incorrect. A model may fabricate a statistic, misattribute a quote, or describe a process that does not exist — with the same tone it uses when it is right. Human review is essential for any output where factual accuracy is critical.
Knowledge cutoff – Pre-training has a fixed endpoint. Anything that occurred after the training data was collected — recent earnings results, regulatory changes, new product launches — is invisible to the model unless explicitly provided in the prompt or retrieved via external tools. This is why RAG has become standard practice in enterprise deployments: it extends the model’s effective knowledge by injecting current information at inference time.
Reasoning limitations – Language models can appear to reason — and often do so impressively — but they are fundamentally pattern-matchers, not formal reasoning engines. They can struggle with multi-step arithmetic, strict logical deduction, and tasks requiring precise state tracking across many steps. Techniques like chain-of-thought prompting and tool use help significantly, but do not fully eliminate these gaps.
Context boundary effects – Information near the beginning of a very long context can receive less effective attention than recent inputs, leading to inconsistencies in long-document tasks. Prompt design and document chunking strategies can mitigate this.
For organisations, the practical conclusion is this: language models are most powerful when paired with human oversight, structured validation, and well-designed workflows — not when treated as autonomous sources of truth.
Why Language Models Matter for Business
Language models are often viewed as tools for generating text—writing emails, summarizing documents, or answering questions. But in a business context, their role is far more significant.
Language models are not just AI tools—they are decision enablers.
At their core, they transform how organisations interact with data, insights, and knowledge. Instead of navigating dashboards, reports, and fragmented systems, business users can engage with information conversationally — asking questions, exploring scenarios, and receiving contextual answers in real time.
Where Language Models Create Business Value
- AI-Driven Insights and Narratives – Language models transform complex data into clear, human-readable insights. Instead of static dashboards, leaders receive automated performance summaries, root-cause explanations, and forward-looking narratives. This shifts analytics from data consumption to insight-driven action
- Conversational Analytics – Business users no longer need to rely on predefined reports or technical teams. They can simply ask questions such as “Why did sales decline this quarter?” or “Which channels are driving growth vs last year?” Language models interpret intent, query underlying data, and generate contextual responses—democratizing analytics across the organization.
- Enterprise Copilots – Language models act as intelligent assistants embedded within workflows. They support sales teams with account insights, marketing teams with campaign recommendations, and supply chain teams with demand signals. Instead of searching for information, teams receive proactive, contextual guidance.
- Decision Intelligence Platforms – The most advanced application integrates language models into decision systems that combine internal and external data, business logic — KPIs, rules, models — and AI reasoning. The outcome is not just answers but actionable recommendations that guide decisions at every level of the organization.
The Real Value
Organizations that leverage language models effectively can scale expertise across the enterprise, reduce time to insight, improve decision quality, and align teams around a single version of truth.
The true value of language models is not in generating text—it is in enabling faster, better, and more consistent decisions.
Language models are redefining how businesses operate — not by replacing human judgment, but by augmenting it. Organisations that deploy them effectively can scale expertise across the enterprise, compress time-to-insight, improve decision quality, and align teams around a shared, real-time understanding of performance. In an era defined by the speed of information, that is a durable competitive advantage.

Leave a comment