
Every AI system you interact with today—ChatGPT, copilots, enterprise AI—relies on one simple idea: predicting the next word. This seemingly simple mechanism, when scaled, becomes one of the most powerful technologies of our time
Before we jump into Large Language Models (LLMs), it’s important to first understand what a Language Model (LM) is—and why it matters.
What is a Language Model?
A Language Model is a probabilistic system that learns patterns in language and assigns likelihoods to sequences of words (or tokens).
At its core, it answers a simple but powerful question – “How likely is this sequence of text?”
Language models achieve this by learning statistical regularities from massive text corpora—capturing grammar, structure, context, and meaning in human language.
Mathematical Foundation
A language model is not a database of knowledge—it is a system for modeling language as probability. Formally, a language model defines a probability distribution over a sequence of words:
From Probability to Prediction
This equation may look mathematical, but conceptually it means something simple: the model builds a sentence one word at a time, always using prior context. A language model decomposes the probability of a sequence using the chain rule, expressing it as a product of conditional probabilities:
In simple terms, the model predicts each token based on all the tokens that came before it. This step-by-step prediction process is the core mechanism behind autoregressive text generation.
This means – Given previous words, predict the next word Repeat this process to generate full sentences, This means that every possible sentence can be assigned a probability. More natural and meaningful sentences tend to have higher probabilities, while incorrect or incoherent sequences have lower probabilities. This simple yet powerful idea underpins everything from basic autocomplete features to modern AI systems.
For Example Consider the sentence: “The sun rises in the”
A language model might assign probabilities like:
- east → 0.85
- west → 0.10
- sky → 0.04
- banana → ~0.00
The model selects or samples from these probabilities to generate text.
Tokens: The Building Blocks of Language
Language models do not process raw text directly—they operate on tokens, which are smaller units of text. These tokens are typically subword units, rather than full words, allowing models to handle language more efficiently and flexibly. A token can represent:
- A full word (e.g., “sales”)
- A subword (e.g., “trans” + “form”)
- Or even a character in some cases
Examples of Tokenization
- “transforming” → “transform” + “ing”
- “unbelievable” → “un” + “believ” + “able”
- “globalization” → “global” + “ization”
- “AI-driven” → “AI” + “-” + “driven”
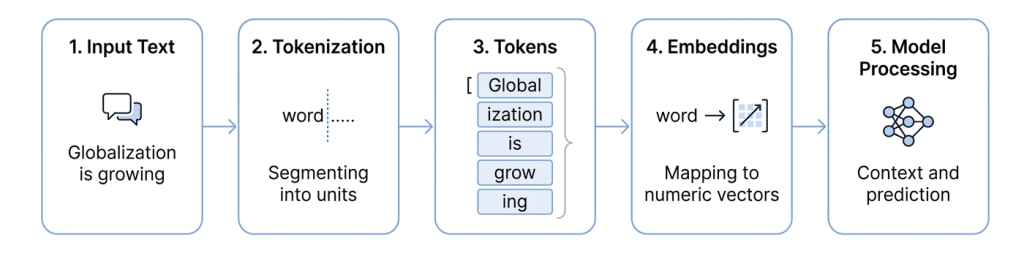
Why Sub-word Tokenization Matters
Modern language models use techniques such as Byte Pair Encoding (BPE) or WordPiece to break text into subword tokens. This design provides several key advantages:
- Efficient vocabulary management – Instead of storing millions of full words, models operate with a manageable vocabulary (typically ~30K–100K tokens).
- Handling unseen or rare words – New or uncommon words can be broken into known sub-words, allowing the model to still interpret them effectively.
- Better generalization across domains – Whether it’s business terms, product names, or technical jargon, sub-word tokenization enables flexibility.
- Language-agnostic capability – The same approach works across multiple languages, making models scalable globally.
- Efficient computation – Smaller, reusable token units make training and inference more efficient.
Language models do not “read words” the way humans do; instead, they process patterns of tokens. As a result, they can understand and generate new words they have never explicitly seen before, adapt seamlessly across different industries such as retail, finance, and healthcare, and operate across multiple languages using the same underlying architecture.
Embeddings: Converting Language into Meaning
Before any processing begins, tokens are transformed into numerical representations known as embeddings.
These embeddings capture the semantic meaning of language by representing words and subwords as vectors in a high-dimensional space. As a result, tokens with similar meanings are positioned closer together, enabling the model to understand relationships, context, and nuances.
👉 This transformation is what makes language computable, allowing models to move from raw text to meaningful interpretation and prediction.
What Does a Language Model Actually Learn?
What emerges is not memorization, but a compressed representation of how language—and to some extent, the world—behaves.
At its core, a language model does not memorize sentences—it learns patterns and structures of language from massive text data. Specifically, it learns:
- Statistical relationships between words → which words tend to appear together
- Grammar and syntax → how sentences are structured correctly
- Contextual meaning → how meaning changes based on surrounding words
- Long-range dependencies → how earlier parts of a sentence influence later parts
- Usage patterns and style → tone, phrasing, and domain-specific language
In essence, a language model builds a probabilistic map of language, allowing it to generate text that is coherent, context-aware, and human-like.
In simple words, a language model does not “store knowledge” like a database—it learns how language behaves. This is why it can:
- Generate entirely new sentences
- Occasionally produce fluent but incorrect responses
- Adapt to different contexts and tones
The Transformer + Attention: Engine Behind Modern Language Models
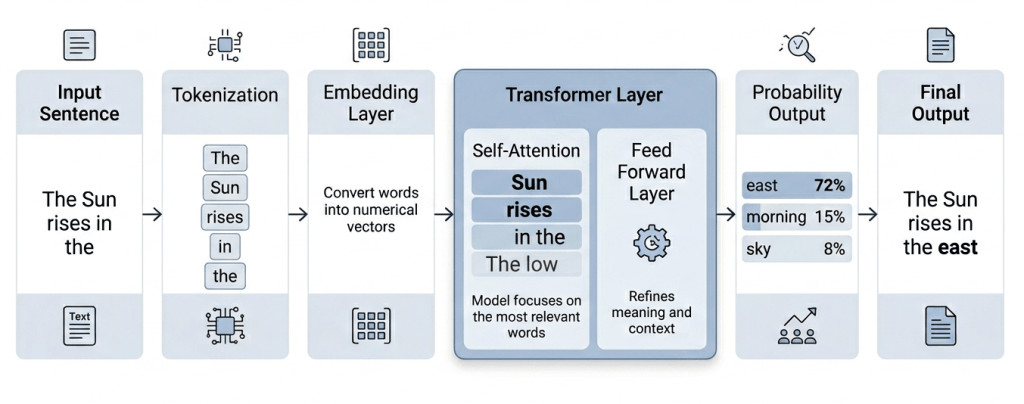
The Transformer architecture is the core engine behind modern language models. It enables models to process entire sequences of text simultaneously and learn relationships between words efficiently.
At a high level, the process works as follows:
- Input tokens are converted into embeddings, which represent words as numerical vectors
- These embeddings pass through multiple Transformer layers, each refining the model’s understanding of context
- Within each layer, the model uses self-attention to determine how much focus to give to different tokens in the sequence
- The output is a set of contextualized representations, which are then used to predict the next token
Attention: How Models Understand Context
The key innovation in Transformers is self-attention.
Instead of reading text sequentially, the model:
👉 Looks at all tokens simultaneously
👉 Decides which ones are most relevant
Technically:
- Each token generates Query, Key, and Value vectors
- Attention scores are computed using similarity (dot product)
- Scores are normalized using softmax
Example – “The Sun rises in the …” The model focuses more on:
- “Sun” → high importance
- “rises” → high importance
- Leading to prediction: “east”
👉 Unlike earlier models that processed text sequentially, Transformers analyze the entire context at once—making them significantly more powerful for understanding language.
Pre-training and Adaptation
Modern language models are built in two stages:
- Pre-training – Learn general language patterns from massive datasets.
- Adaptation (Fine-tuning / Prompting) – Specialize for tasks, domains, or behaviors. Techniques include:
- Instruction tuning
- Reinforcement Learning from Human Feedback (RLHF)
Context Window: Why It Matters
The context window defines how much text a language model can consider at a time when generating or understanding output. At a high level:
- The model takes in a sequence of tokens (prompt + prior outputs)
- It can only “see” and use information within this fixed window
- Everything outside this window is effectively ignored
Why Context Window Is Important
- Better understanding of long inputs – Larger context windows allow the model to process longer documents, conversations, and reports without losing earlier information.
- Improved coherence and continuity – The model can maintain context across multiple steps, leading to more consistent and relevant responses.
- Enhanced reasoning and analysis – With more context, the model can connect information across sections—critical for tasks like summarization, diagnostics, and decision support.
The context window determines how much the model can “remember” at any given moment. As context windows grow, language models become more capable of handling complex, real-world tasks that require deeper understanding and continuity.
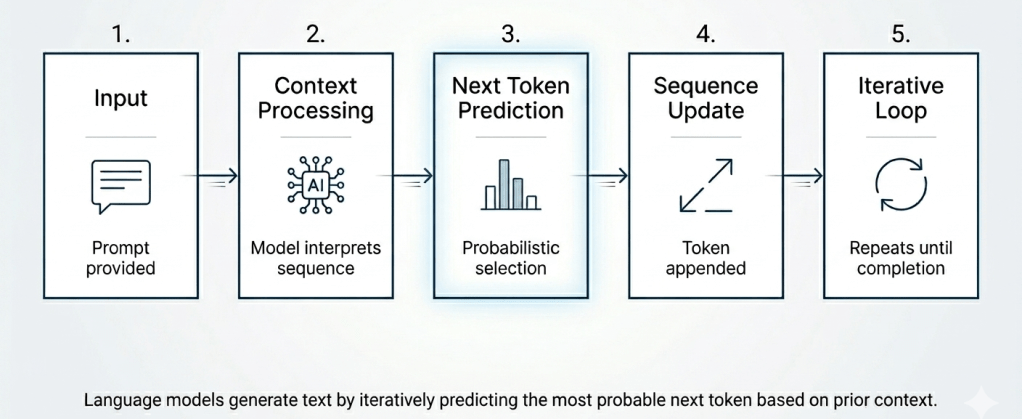
How Language Models Generate Text
Language models generate text using a continuous loop:
Why Language Models Matters for Business
Language models are often viewed as tools for generating text—writing emails, summarizing documents, or answering questions. But in a business context, their role is far more significant.
👉 Language models are not just AI tools—they are decision enablers.
At their core, they transform how organizations interact with data, insights, and knowledge. Instead of navigating dashboards, reports, and fragmented systems, business users can now engage with information conversationally—asking questions, exploring scenarios, and receiving contextual answers in real time.
Where Language Models Create Business Value
- AI-Driven Insights and Narratives – Language models transform complex data into clear, human-readable insights. Instead of static dashboards, leaders receive automated performance summaries, root-cause explanations, and forward-looking narratives. This shifts analytics from data consumption to insight-driven action
- Conversational Analytics – Business users no longer need to rely on predefined reports or technical teams. They can simply ask questions such as “Why did sales decline this quarter?” or “Which channels are driving growth vs last year?” Language models interpret intent, query underlying data, and generate contextual responses—democratizing analytics across the organization.
- Enterprise Copilots – Language models act as intelligent assistants embedded within workflows. They support sales teams with account insights, marketing teams with campaign recommendations, and supply chain teams with demand signals. Instead of searching for information, teams receive proactive, contextual guidance.
- Decision Intelligence Platforms – The most advanced application integrates language models into decision systems that combine data (internal and external), business logic (KPIs, rules, models), and AI reasoning. The outcome is not just answers, but actionable recommendations that guide decisions.
The Real Value
Organizations that leverage language models effectively can scale expertise across the enterprise, reduce time to insight, improve decision quality, and align teams around a single version of truth.
The true value of language models is not in generating text—it is in enabling faster, better, and more consistent decisions.
Language models are redefining how businesses operate—not by replacing humans, but by augmenting decision-making. In the age of AI, competitive advantage will come from how effectively organizations turn language into decisions. Organizations that leverage them effectively can scale expertise across the enterprise, reduce time to insight, improve decision quality, and align teams around a single version of truth.

Leave a comment